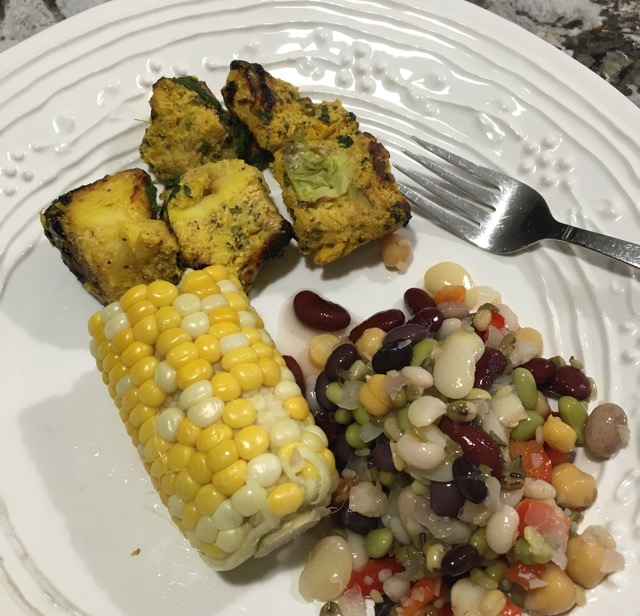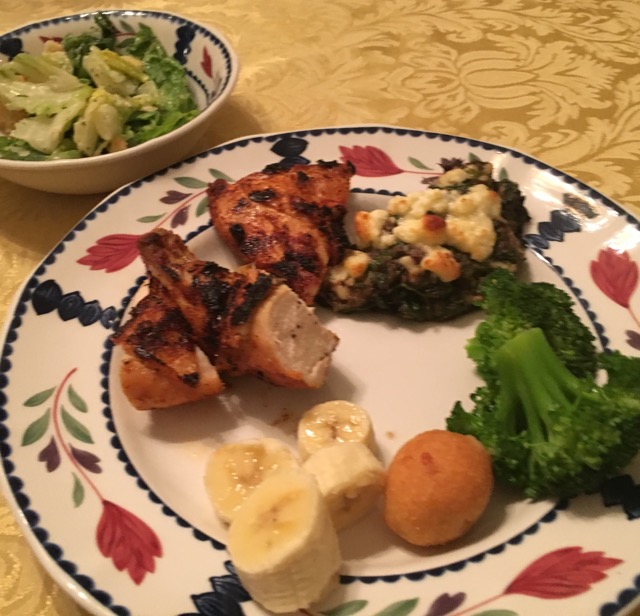Captioning Images of Food
Nourishly vs Cloud Vision vs Clarafai

Note 1: The Nourishly model is built from just phase one training of im2txt. Phase two is still running. We've also got another 150k captioned images to throw into the training once we've finished our appraisal of this test run. Our DB of captioned images grows by 10k week. We anticipate that growth will be faster once we launch the Nourishly product out of beta. (Currently data comes from our RR product)
Note 2: The API is a little slow as we're using a CPU not GPU to do the inferencing as all our GPUs are maxed out training data